关于线程池
并发总是离不开多线程,多线程的应用能够更好地帮助我们协调利用CPU、Memory、Net、I/O等系统资源。频繁的创建、销毁线程会浪费大量的系统资源,增加并发编程的风险。利用线程池可以实现类似主次线程隔离、定时执行、定时执行、周期执行等任务。作用包括:
- 利用线程池管理并复用线程、控制最大并发数等。
- 实现某些与时间相关的功能,如定时执行、周期执行等。
- 隔离线程环境。比如交易服务和搜索服务在同一台服务器上,分别开启两个线程池,交易线程的资源消耗明显要更大;因此,通过配置读的线程池,将两者隔开,避免个服务线程相互影响。
关于线程池的基础概念和一些简单场景,可以看看这篇文章:线程池开门营业招聘开发人员的一天
迷思
如下是我定义的一个线程工具类,我定义了核心线程数量大小为4;最大核心线程数量大小为8,LinkedBlockingQueue容量大小未初始化,也未定义一个handle,当我在利用这个线程池生产线程的过程中发现,当创建速度大于它的处理速度时,核心线程数量依旧是4个。
嗯?说好的,最大核心线程数不是BUG,8个吗?难道当前不应该是8个?
1 | public class ThreadPoolUtils { |
探究
看来还是basic不够扎实啊,学的是个JB!我们看一下ThreadPoolExecutor的源码,查看下的他的4个构造方法如下图,我们来看看比较难懂的几个参数:

- 第5个参数:
workQueue表示缓存队列。当请求的线程大于maximumPoolSize时,线程进入BlockingQueue阻塞队列。是一个生产消费模型队列。 - 第7个参数:
handle表示执行拒绝策略的对象。当超过第5个参数workQueue的任务缓存区上限的时候,就可以通过该策略处理请求,是一种简单的限流保护。
那么,我们上面的实例化是怎么写的?
1 | // 创建线程池1 |
我们把LinkedBlockingQueue<Runnable>()作为缓存队列,我们不关心的它内部实现,通过源码可以知道它是一种无限队列,构造器容量默认值大小是Integer.MAX_VALUE,往往在生产场景中很难达到这个值,所以像我上面这样写是极其不科学的,应该根据实际场景设置一个可承载容量大小,并配合handle做出拒绝策略,才是一个完整的流程。
我们稍微熟悉了它的构造方法之后,怎么知道它是如何工作的呢?另外我之前的迷思,为什么核心线程数始终等于4呢?
原因
首先我们可以通过源码查看execute方法:
1 | public void execute(Runnable command) { |
而addWorker方法主要是动态的调整线程池的线程数量。从execute方法和addWorker方法可以看出,当前线程数优先与corePoolSize 比较,大于corePoolSize ,则与workQueue容量比较;如果当前线程数大于workQueue容量,则与maximumPoolSize比较;如果当前线程数大于maximumPoolSize,则执行饱和策略;最后,根据饱和策略做出相应的处理。
所以我粗略的总结下当corePoolSize(核心线程数)满了,接下来的线程先进入workQueue(任务队列),当队列也满了之后,创建新线程,直到达到maximumPoolSize(最大线程数),之后再尝试创建线程时,会进入拒绝rejectedExecution。
所以为什么线程池的核心线程数一直是4个,因为多余的都处在任务队列阻塞中,由于未设置一个容量大小,所以这个容量非常的大,其实是超出我们的处理能力的,我们程序始终就也没能够达到最大线程数。或者可以这么理解,这个maximumPoolSize算是一种比较坏(极限)的情况,很少情况并不会真的按照这个数量处理任务,只有当任务队列都不够时,才会继续创建线程,直到达到最大线程数,超过了之后就必须要handle来处理拒绝策略了。
饱和拒绝策略
好吧,面试被问到了有哪些策略,2020.11.4 更新一下。
默认的AbortPolicy:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
1
A handler for rejected tasks that throws a {@code RejectedExecutionException}.
这是线程池默认的拒绝策略,在任务不能再提交的时候,抛出异常,及时反馈程序运行状态。如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时的通过异常发现。
DiscardPolicy
ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。如果线程队列已满,则后续提交的任务都会被丢弃,且是静默丢弃。
1
A handler for rejected tasks that silently discards therejected task.
使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略。例如,本人的博客网站统计阅读量就是采用的这种拒绝策略。
DiscardOldestPolicy
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务。
1
A handler for rejected tasks that discards the oldest unhandled request and then retries {@code execute}, unless the executor is shut down, in which case the task is discarded.
此拒绝策略,是一种喜新厌旧的拒绝策略。是否要采用此种拒绝策略,还得根据实际业务是否允许丢弃老任务来认真衡量。
CallerRunsPolicy
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
1
A handler for rejected tasks that runs the rejected task directly in the calling thread of the {@code execute} method, unless the executor has been shut down, in which case the task is discarded.
如果任务被拒绝了,则由调用线程(提交任务的线程)直接执行此任务。
自定义一个Policy
实际开发中,我们还是会自定义一个Policy策略,比如写入日志、数据库等等。
测试
好了,既然大致了解了线程池的工作原理之后,可以进行一个测试来验证以下是否符合:
1 | public class TestThreadPool { |
一个线程类Task,在run方法中打印一句「正能量」,然后sleep2秒来模拟处理这个任务。我们创建一个核心线程数为4,最大线程数8,容量大小为50的LinkedBlockingQueue队列,然后在循环中持续创建线程。当成功创建完这100个线程之后,应该会有====================end====================打印出来。
我们可以期待一下结果是什么?
按照上面的工作流程来说,有几种情况:
- 线程处理的速度远远大于线程创建的速度,可能4个核心数都完全够用,甚至用不到
workQueue,最后打印了end。emmm,当然从我们写的测试代码来说几乎是不可能的,for循环表示:烙呢?中国🇨🇳速度嗷! - 线程创建的速度大于回收速度,但是
workQueue和maximumPoolSize完全可以支撑,100个线程创建成功并完成任务。 - 当
corePoolSize和workQueue以及maximumPoolSize都过载,丢弃任务并抛出RejectedExecutionException异常了。
其实可以很明显知道,sleep2秒加上logger.info()方法,线程的创建的速度一定是大大于执行的。按照4、8、50的配置,当地58个创建被创建成功之后,要是目前没有任何一个线程被释放的话,第59个线程会因为上限问题而被拒绝,这时候就会抛出异常了。当然这是个for循环,产生的速度足够快,基本上100次循环完成,第一个线程都没完成,所以可以大胆猜测,logger一共会打印58行日志,并伴随着RejectedExecutionException的出现。
我们看一下运行的结果:
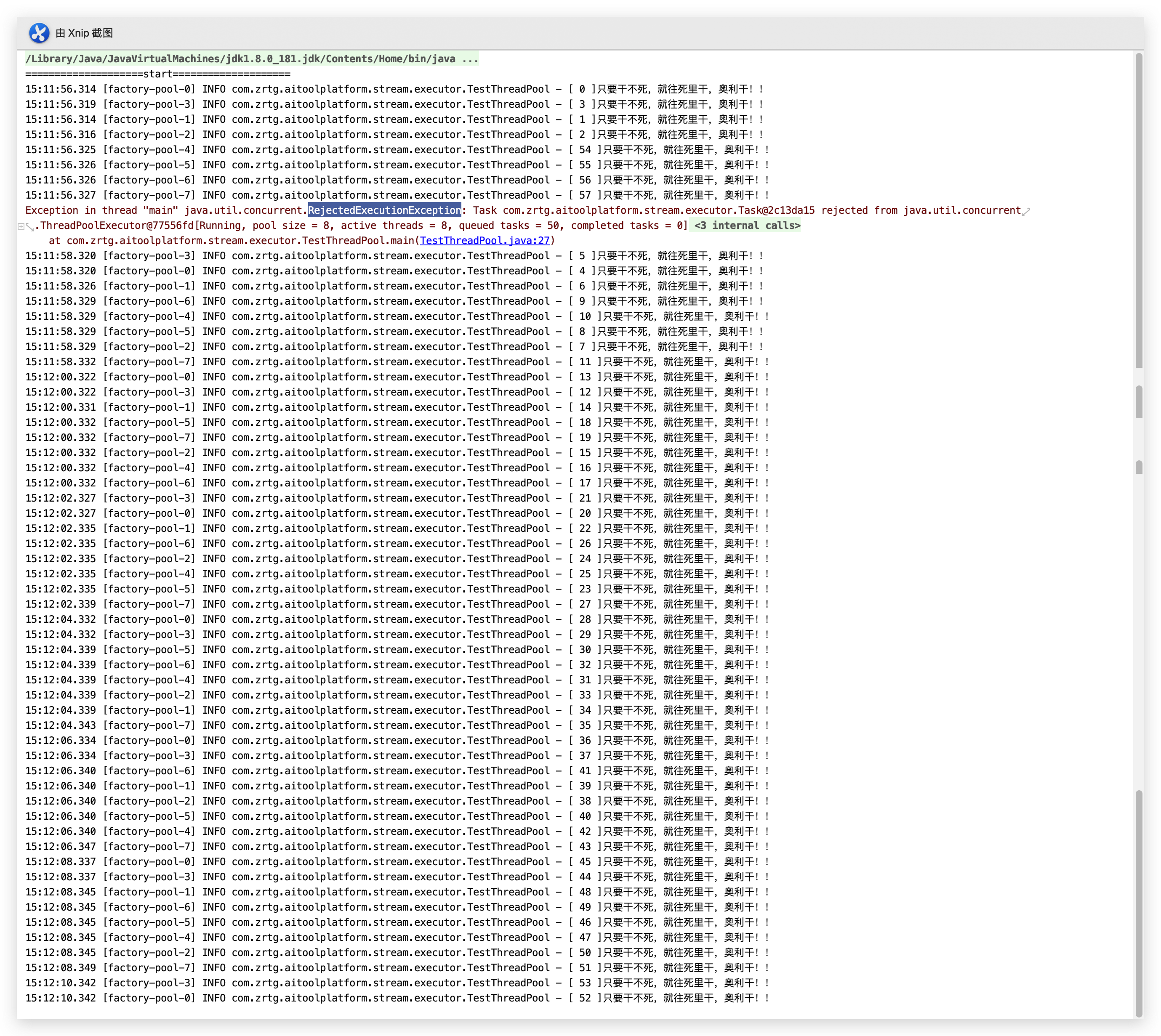
果然第58个线程被创建之后,后续第59个线程想被创建就抛出了异常,如图刚好是58行(0 ~ 57),也没有====================end====================的出现。
奥利给
当我们把这个线程类的run方法分别改成如下:
1 |
|
1 |
|
分别看下结果:

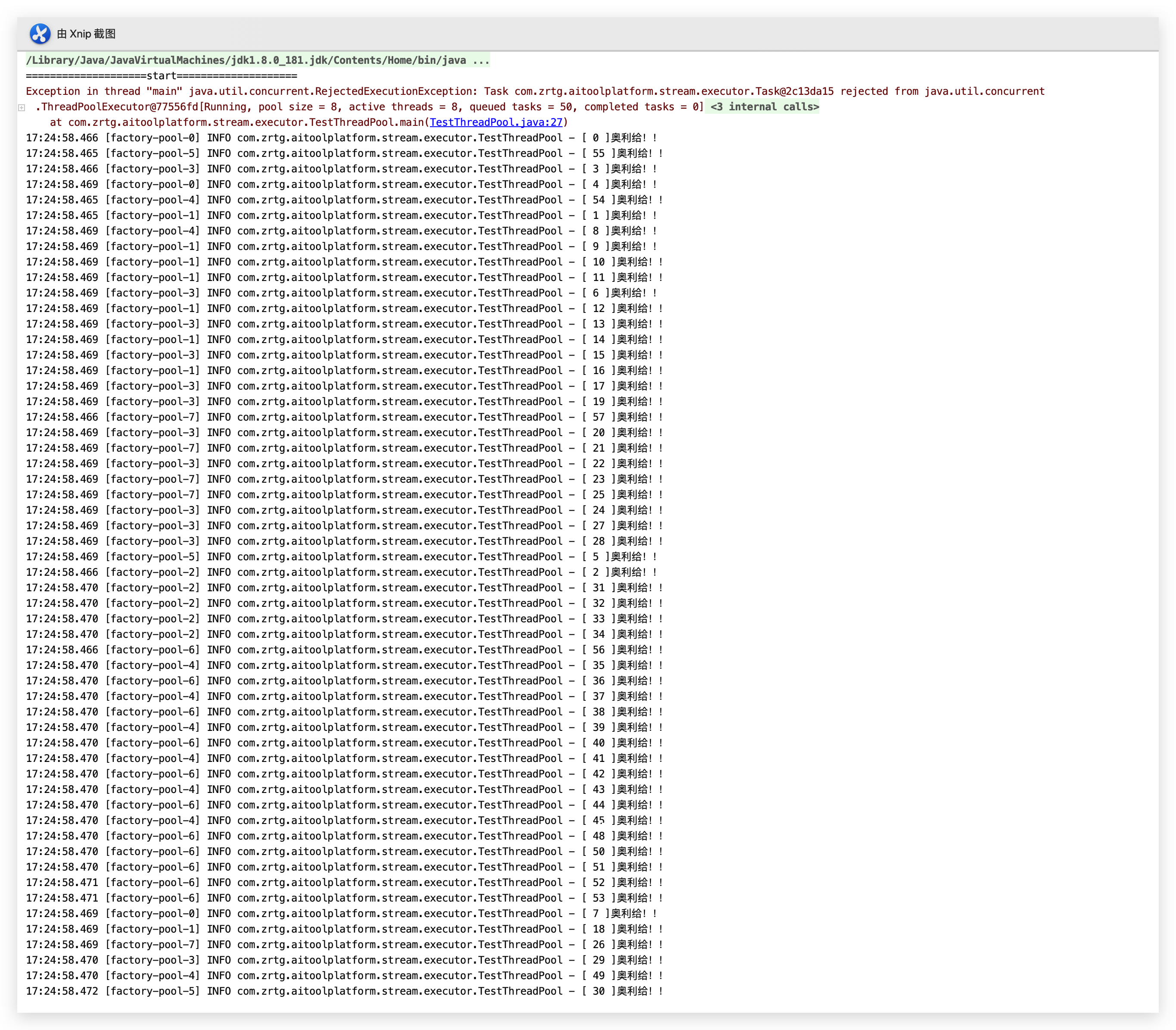
看来org.slf4j.Logger.info()的耗时不是一般的长,比System.out.println()还长。